POLCA: Stochastic Generative Optimization with LLM
Prioritized Optimization with Local Contextual Aggregation — a provably scalable search algorithm for LLM-based generative optimization under stochasticity.
POLCA is a search algorithm for generative optimization with LLMs. Given a fixed LLM as a black-box proposal oracle, it improves a parameterized program — an agent prompt, a piece of Lean 4 code, a CUDA kernel — by deciding how that oracle's proposals are evaluated, stored, and fed back. We are not proposing a better LLM optimizer; the contribution is the search loop around it (a priority queue, an ε-Net filter, and a summarizer), which works with any current or future model and admits a convergence guarantee under evaluation stochasticity. Across τ-bench, HotpotQA, VeriBench, and KernelBench, POLCA outperforms GEPA, OpenEvolve, and DSPy in both speed and final score.
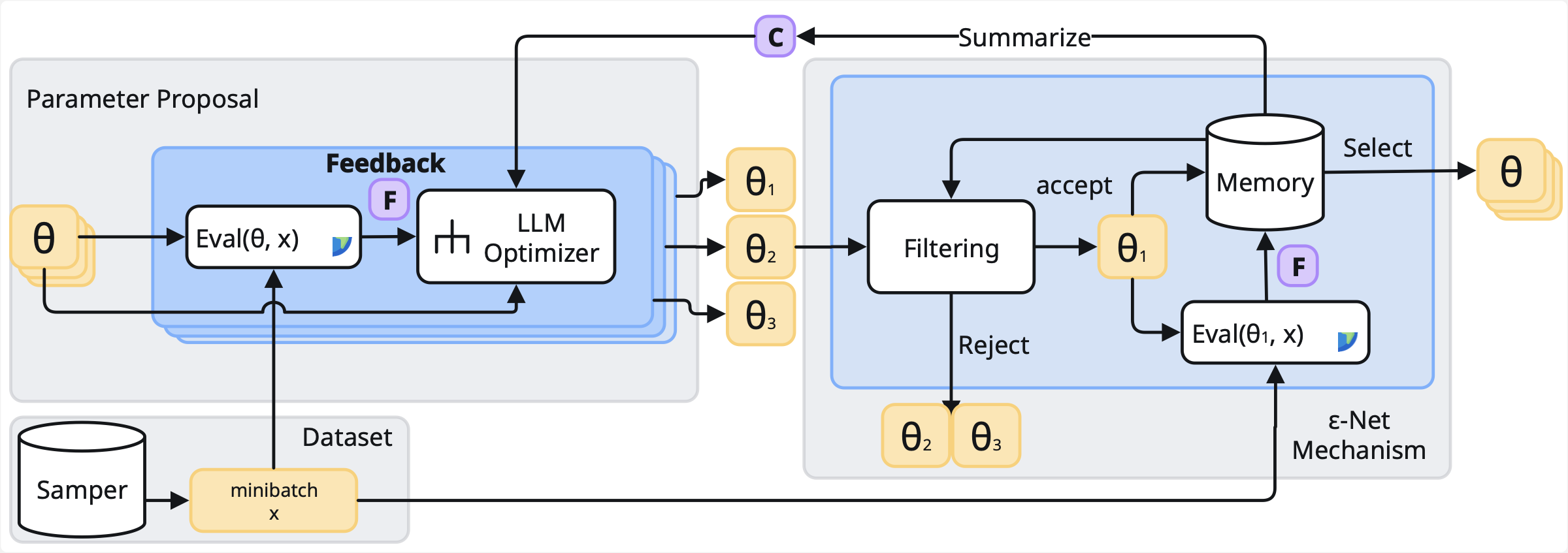
Figure 1. The POLCA loop. A memory buffer is maintained as an ε-Net of diverse programs. Each iteration (1) selects promising candidates by priority, (2) evaluates them on a sampled minibatch, (3) proposes new candidates from the feedback, (4) filters them by semantic distance and integrates the survivors, then (5) summarizes the memory into a concise global context for the next cycle.
02Two challenges
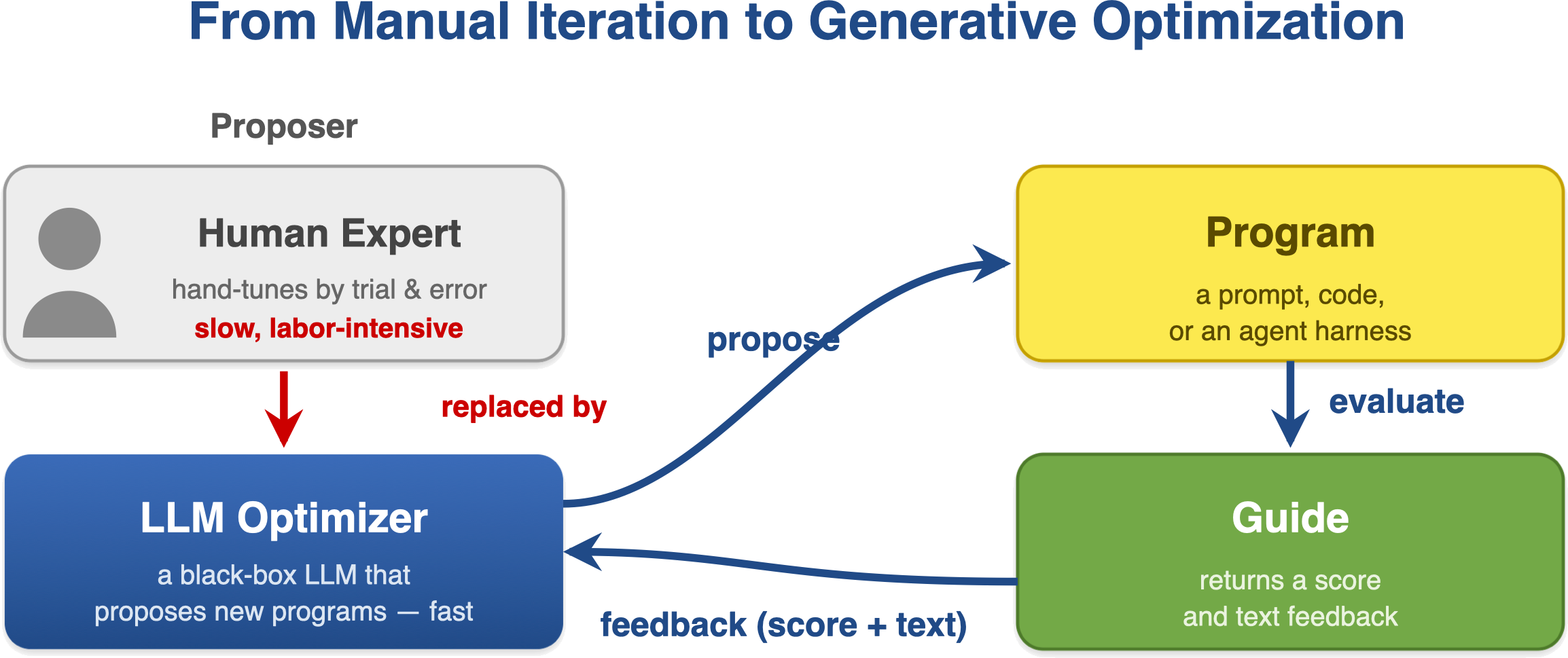
We study stochastic generative optimization of a parameterized program \(P_\theta\): an LLM optimizer replaces the human expert in the tuning loop — it proposes candidates, a guide scores them and returns text feedback, and we want the best program under a fixed budget.
Figure 2. The loop shared by most self-evolving-agent systems. Two problems in it are usually left unhandled.
Challenge 1 · Stochasticity
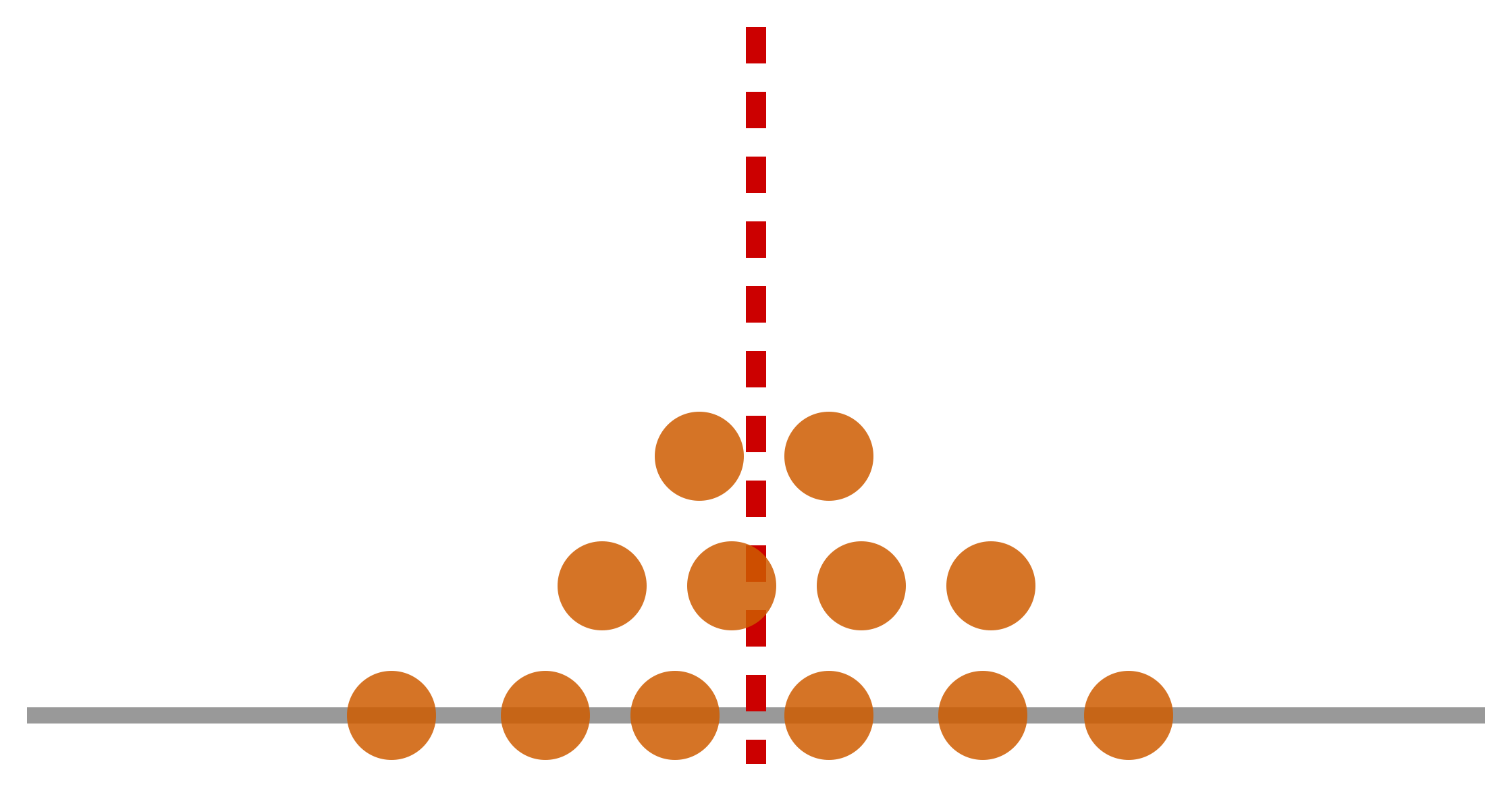
The same program scores differently every time — from the sampled minibatch, the program's own execution, and a stochastic evaluator. One evaluation just fits the noise; a reliable estimate of the true reward \(\mu(\theta)\) needs many.
Figure 3. Noisy scores of one program scatter around its true value \(\mu(\theta)\).
Challenge 2 · Duplication
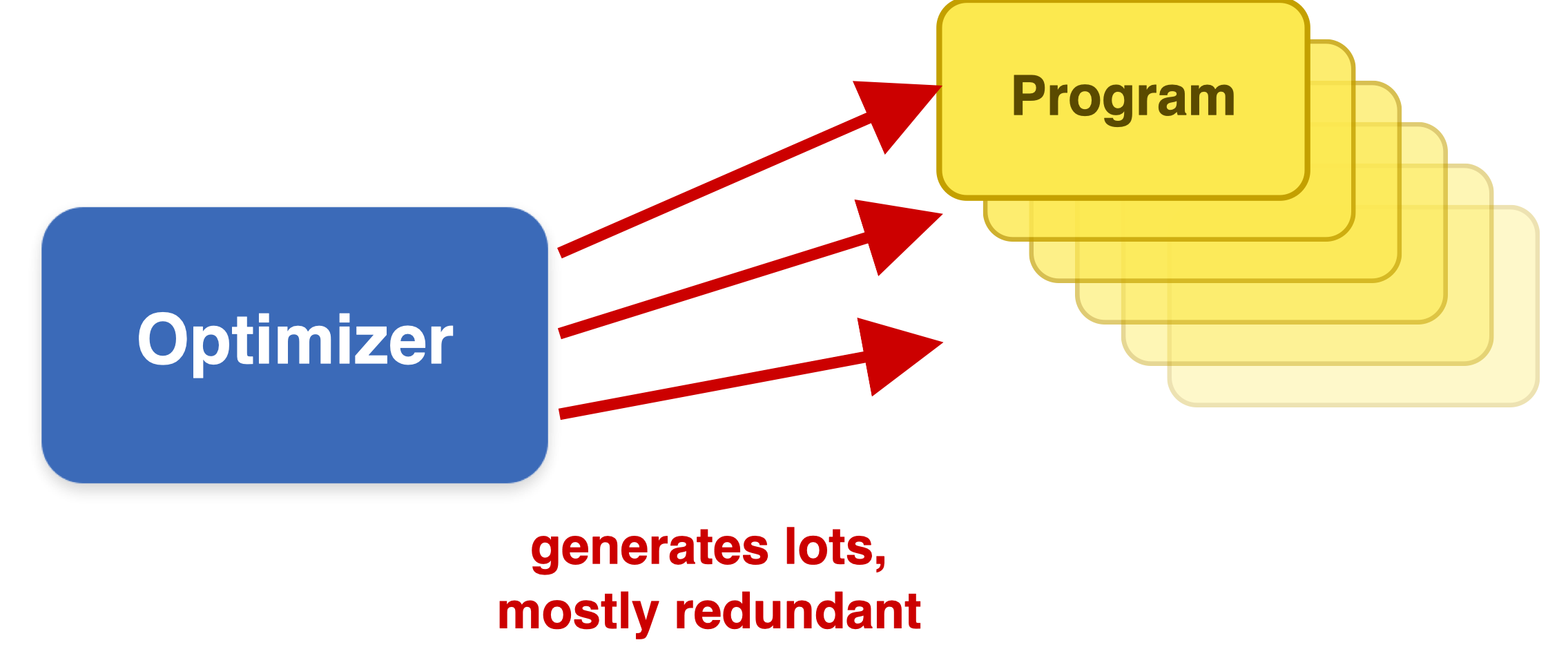
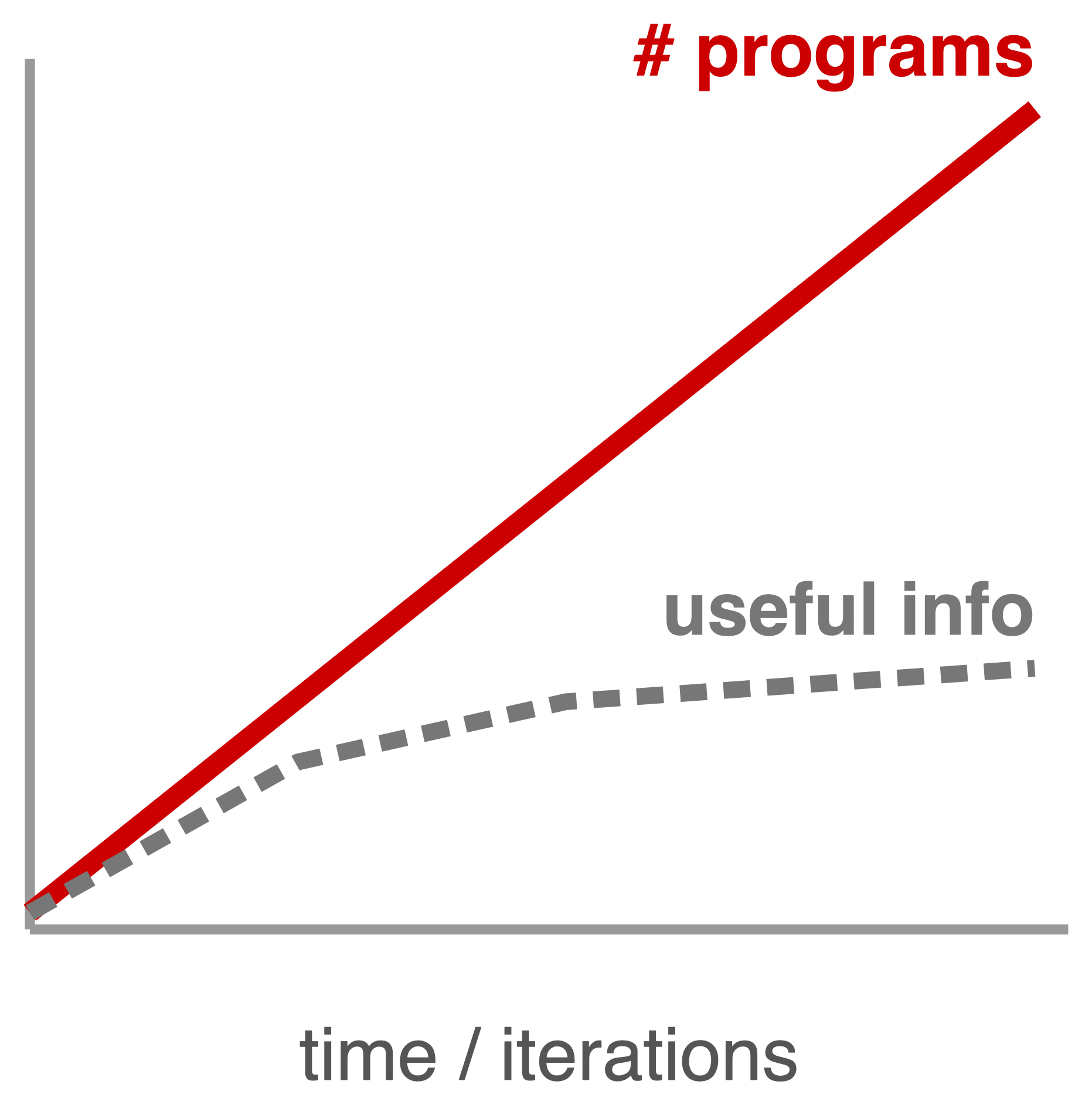
Prompted with similar context, the optimizer emits many near-identical candidates: the candidate count grows linearly while distinct information does not. Combined with Challenge 1 — each program already needs many evaluations — scoring every near-duplicate becomes intractable.
Figure 4. The optimizer keeps generating redundant programs; useful information stays flat. POLCA's fix — the ε-Net (§03) — keeps memory a bounded, diverse cover of size \(N_\varepsilon\).
03Method
POLCA is best read as a framework, not a fixed pipeline. It coordinates four roles — a memory, a similarity filter, a proposer, and a summarizer — and prescribes how they interact, while leaving each role's internal implementation open. The analysis in the next section then asks a precise question: given any fixed choice of these components, why is the resulting search procedure efficient?
One iteration
Each iteration samples a minibatch \(\mathcal{B}\) from the dataset, selects the highest-priority programs from the queue, and evaluates them on \(\mathcal{B}\) to refresh their statistics. The optimizer then proposes new candidates from this fresh feedback plus a global summary; surviving the similarity filter, they are evaluated on the same \(\mathcal{B}\) (for a fair comparison) and merged into memory. A summarize step finally compresses memory into the context used next round. The remaining subsections explain each role and what is — and is not — fixed about it.
Priority-queue memory — handles stochasticity
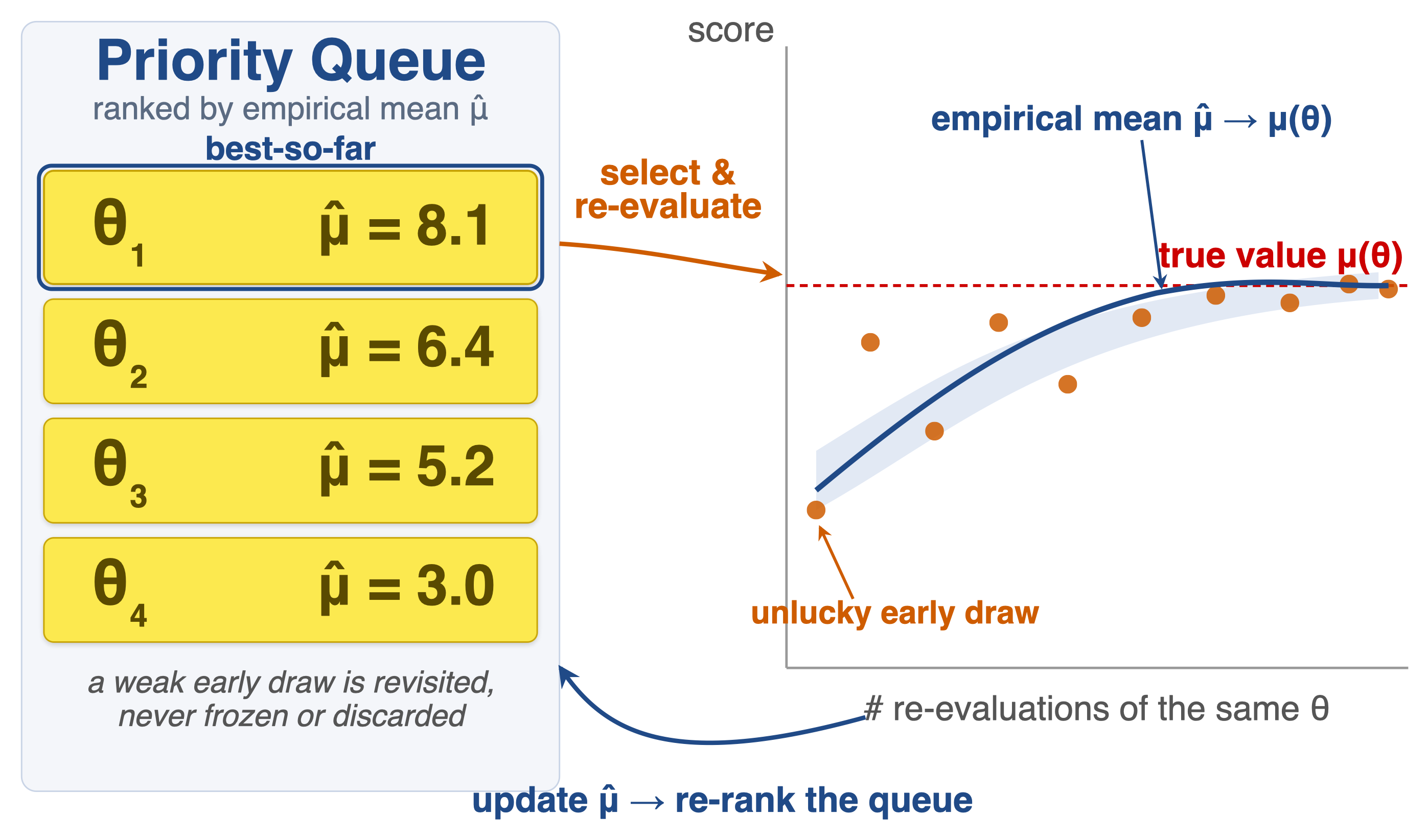
Every candidate carries its full evaluation history and is ranked by a priority — by default the empirical mean, which concentrates toward \(\mu(\theta)\) as a program is re-selected and re-evaluated. So a candidate that looked weak under an unlucky early draw is revisited, not discarded. (The priority is a knob: a UCB score gives the optimistic exploration used in the theory.)
Figure 5. The queue never freezes a score: re-evaluating a program drives its empirical mean \(\hat\mu\) toward the true value \(\mu(\theta)\), then re-ranks the queue.
ε-Net: a semantic filter — handles duplication
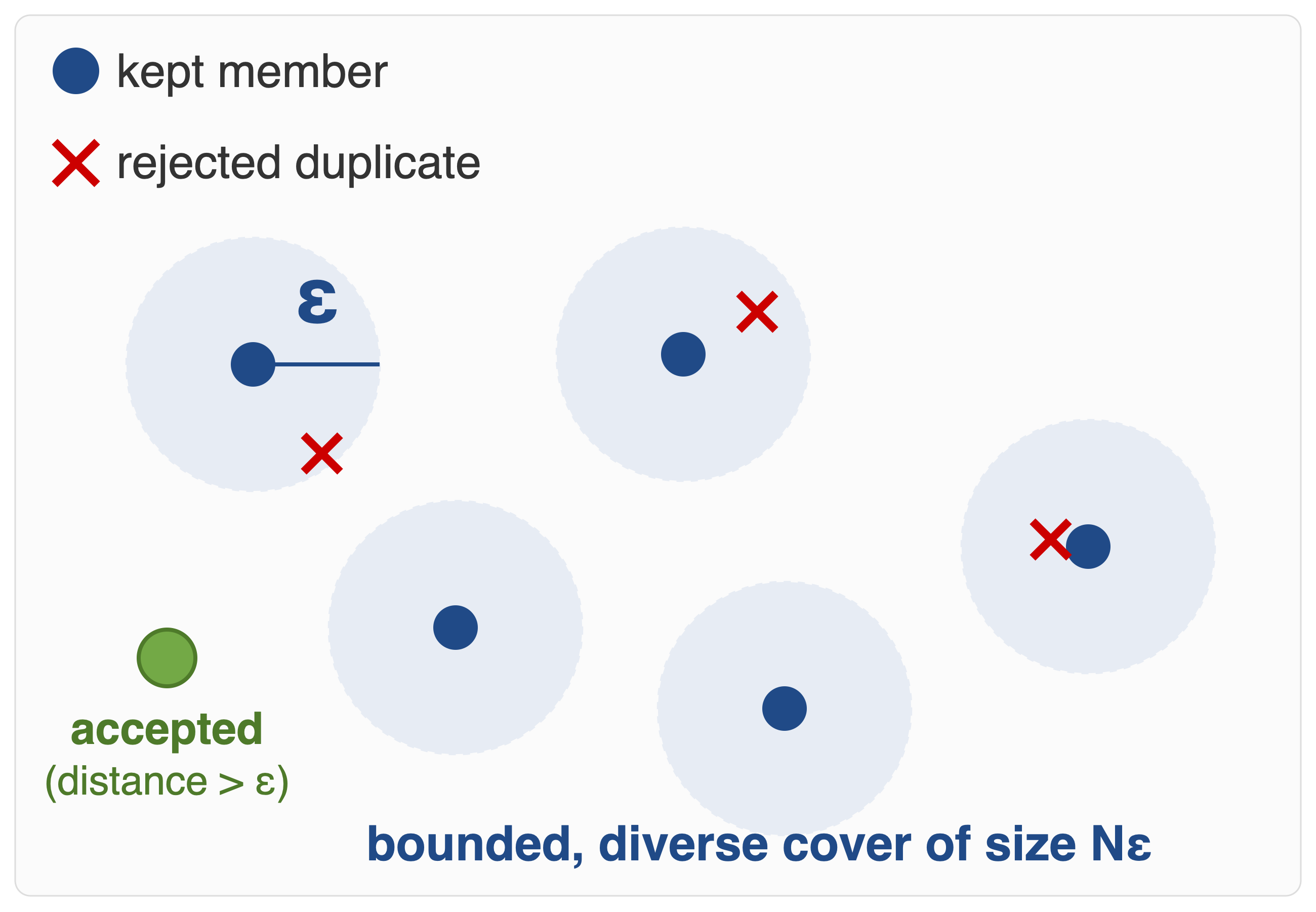
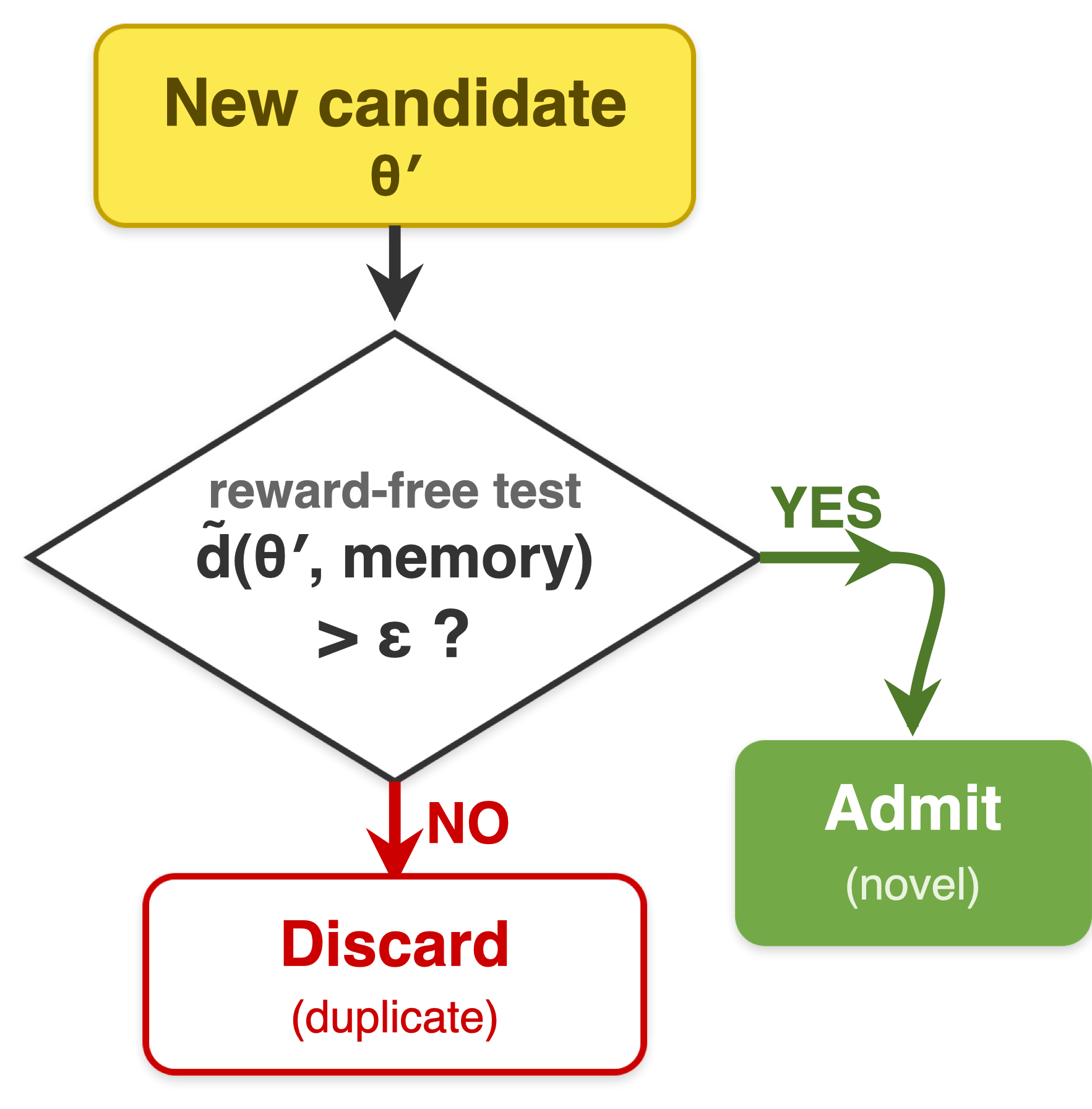
A new candidate is admitted only if it is farther than \(\varepsilon\) from every program in memory, under a similarity \(\tilde d(\cdot,\cdot)\). Memory stays a bounded, diverse cover of size \(N_\varepsilon\) — set by \(\varepsilon\) and the space, not the iteration count. The test uses a reward-free signal, so de-duplication is unaffected by evaluation noise.
Figure 6.Left: memory as an ε-Net — a bounded, diverse cover of size \(N_\varepsilon\); near-duplicates inside an ε-ball are rejected. Right: the reward-free accept/reject test.
Beyond text embeddings. In this paper we instantiate \(\tilde d\) with distances between frontier text-embedding vectors of each program, which works well because programs with nearby embeddings tend to share similar scores. But nothing in POLCA requires a text embedding — any reasonable way to measure similarity among candidates (a code-structure metric, a behavioral signature, a learned embedding for non-text parameters) can play this role. The key property we rely on is only that the filter is computed from a reward-free signal, so de-duplication does not inherit evaluation stochasticity.
Proposer and summarizer
The proposer is the external LLM optimizer that, given a program together with its feedback, returns a new candidate; the summarizer is an LLM that compresses the whole memory into a compact global context \(c_{\text{history}}\) supplied to the proposer. Conceptually, proposing from the current minibatch alone is a first-order update, while adding \(c_{\text{history}}\) — patterns of success and failure aggregated across many programs — acts like momentum that stabilizes the search and helps escape local optima. Both are treated as black boxes: how the proposer reasons internally, and how the summarizer chooses what to keep, are implementation choices POLCA does not constrain.
Why this modularity matters. POLCA fixes the orchestration — priority-driven selection, ε-Net admission, minibatch re-evaluation, summarized context — and leaves the components (similarity measure, proposer, summarizer, priority) swappable. Our claim is not that any single component is novel, but that this orchestration is provably efficient for whatever components you plug in. That is exactly what Theorem 1 formalizes: it summarizes the proposer by two constants \((\gamma,\delta_0)\) and the similarity filter by \(N_\varepsilon\), and shows the sample complexity decouples into a proposal-quality term and an evaluation-stochasticity term — so improving any one building block tightens its own term without touching the rest.
04Theory
Most self-evolving-agent systems are validated only empirically. Treating the LLM optimizer as a fixed black-box oracle, we instead prove POLCA converges efficiently under evaluation stochasticity. Because the analysis concerns the search procedure rather than the model, the guarantee holds for any optimizer plugged in.
Assumption
We do not model the LLM's internals; we summarize its quality by two constants, \(\gamma\) (how much it can improve) and \(\delta_0\) (how reliably). This is the weakest useful "the optimizer makes some progress" condition — without it the oracle could be adversarial and no search procedure could succeed.
Assumption \(\gamma\)-Strict Improvement
There exist constants \(\gamma > 0\) and \(\delta_0 \in (0,1)\) such that for any program \(\theta\) with \(\mu(\theta) \le B-\gamma\), the optimizer proposes a strictly better candidate with at least constant probability:
Stronger optimizers \(\Rightarrow\) larger \(\gamma\) and \(\delta_0\) \(\Rightarrow\) tighter bounds below. Rewards live in \([0,B]\); each observation is \(\sigma^2\)-sub-Gaussian around its true mean \(\mu(\theta)\).
Theorem 1 — convergence under stochasticity
Run POLCA with a UCB priority for \(n\) iterations, where \(T_\theta(n)\) is the number of times program \(\theta\) is selected and evaluated. We bound the total budget spent on sub-optimal programs (those with \(\mu(\theta)\le B-\gamma\), which the optimizer can still improve); bounding it means POLCA stops paying for them and converges to the near-optimal region \((B-\gamma,\,B]\).
Theorem 1 Total selections of sub-optimal programs
The bound is a sum of two independent costs — one set by the optimizer, one by the task's stochasticity — so it shows which bottleneck dominates a given problem.
Term 1 · Proposal quality
\(\dfrac{B}{2\gamma\delta_0}\,\log n\)
The cost of generating a near-optimal program. It depends only on the oracle's quality \((\gamma,\delta_0)\) — a stronger LLM (larger \(\gamma\), larger \(\delta_0\)) shrinks it — and not on the stochasticity \(\sigma\) or the program-space size. You pay it even with deterministic evaluation.
The cost of distinguishing good from bad under stochasticity. It scales with the reward variance \(\sigma^2\) and with \(N_\varepsilon\), the number of distinct programs the ε-Net admits. Without the ε-Net, \(N_\varepsilon\) would grow with \(n\) and this term would diverge; the ε-Net keeps it bounded.
In the deterministic case (\(\sigma=0\)) Term 2 vanishes and the bound becomes \(B\log(n)/(2\gamma\delta_0)\), independent of the program-space size — the program count costs you only because of evaluation stochasticity.
Theorem 2 — the value of the priority queue
Most existing generative-optimization methods perform sequential updating: at each step the optimizer is shown its most recent proposal and asked to improve it, so the search is a single chain \(\theta_0 \!\to\! \theta_1 \!\to\! \cdots\). The flaw is that the chain has no memory — when the optimizer returns a worse candidate (which happens with probability \(1-\delta_0\)), the next step builds on that worse program, and progress can slide backward. POLCA instead always re-proposes from the best program found so far, which the priority queue tracks for free. With deterministic rewards, the expected number of steps to first reach a near-optimal program (reward in \((B-\gamma,\,B]\)) is:
Exponential versus linear in \(B/\gamma\) (the number of \(\gamma\)-sized improvements needed). Because POLCA's running maximum is non-decreasing, a poor proposal never undoes earlier gains, so it never pays the compounding penalty of a memoryless chain — a large speedup that grows with problem difficulty.
We default to the empirical-mean priority; replacing it with a UCB score adds optimistic exploration and yields the provable guarantee of Theorem 1, but gives only marginal empirical gains (see the ablation and the paper). Full statements and proofs are in the paper.
05Experiments
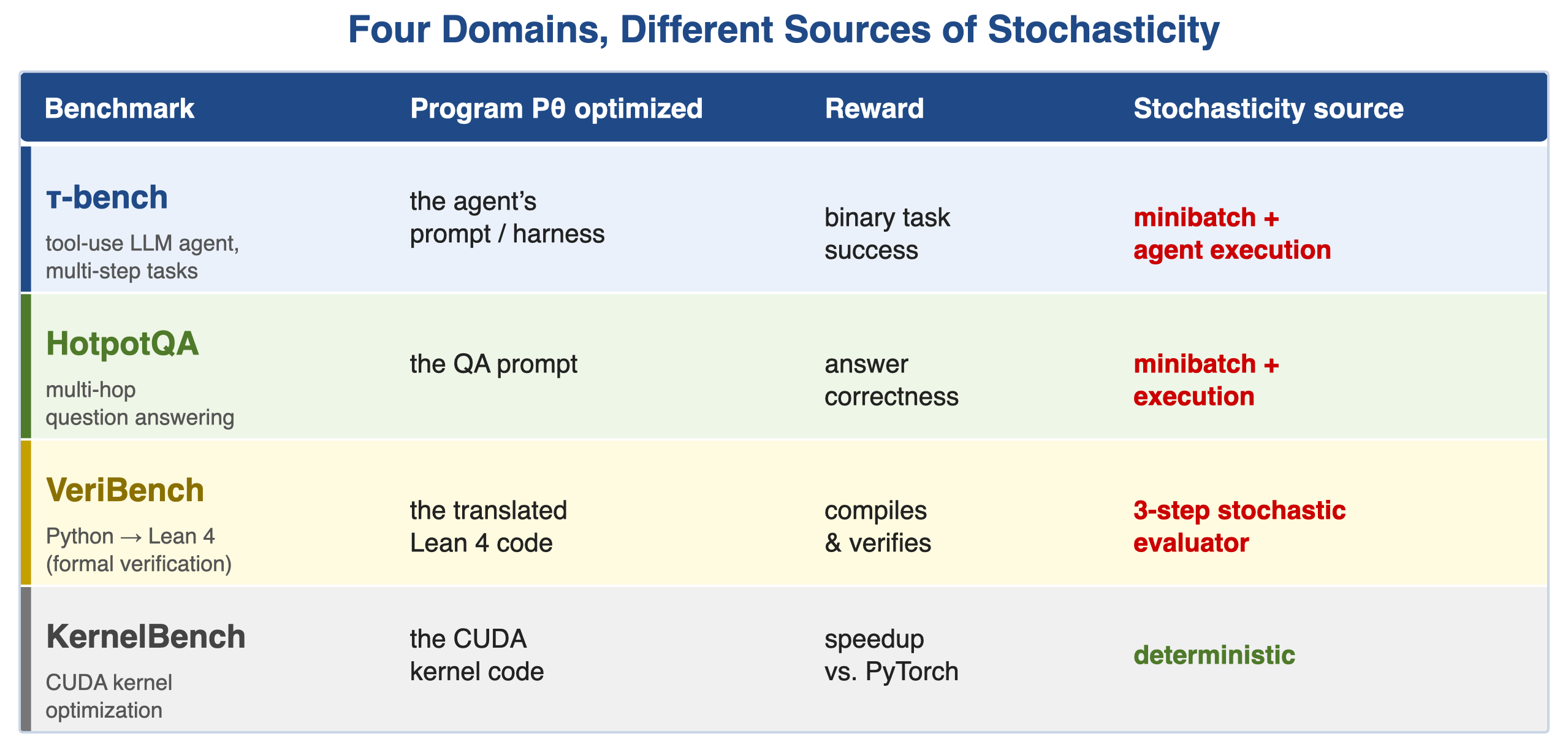
Four benchmarks, each isolating a different source of stochasticity, run in the Trace pipeline with OptoPrime as the optimizer. Baselines are GEPA, OpenEvolve (an open-source AlphaEvolve), and DSPy.
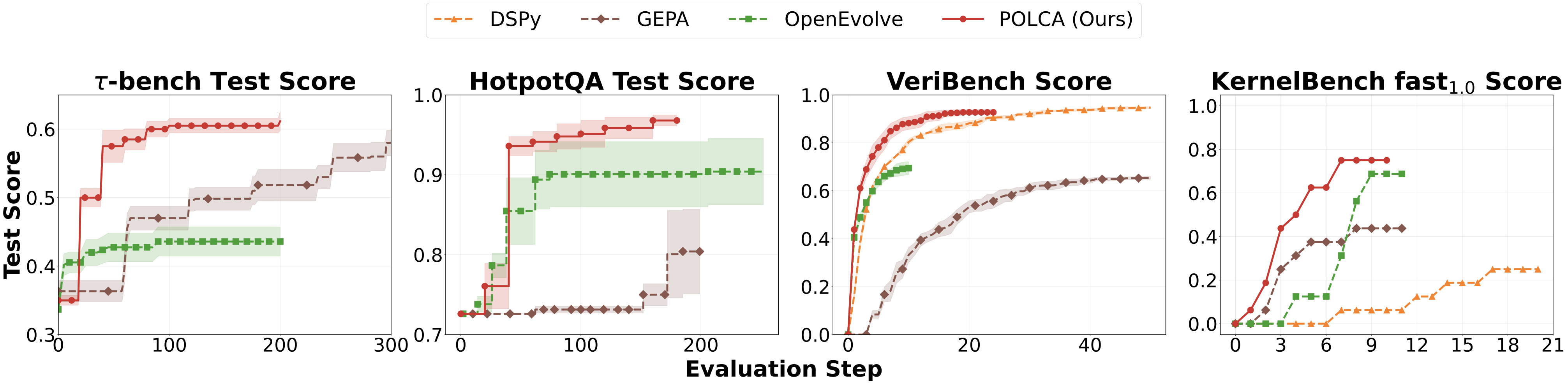
Figure 7. The four domains, each isolating a different source of stochasticity — from noisy agent execution to a fully deterministic evaluator.Figure 8. Search efficiency across all four benchmarks. Solid curves show the average highest score at each evaluation step; shaded regions are the standard error across independent runs (6 seeds for τ-bench, 3 for HotpotQA and VeriBench, 1 for KernelBench). POLCA reaches higher final scores at fewer steps throughout.
τ-bench Pass@1
First 10
Last 105
All 115
Base Prompt
0.348
0.392
0.389
GEPA
0.557
0.417
0.429
OpenEvolve
0.373
0.422
0.418
POLCA (Ours)
0.575
0.425
0.439
Trained on the first 10 tasks; POLCA generalizes best to all 115 (+13% over base).
VeriBench Lean 4 (50 calls/task)
Pass Rate
DSPy
0.888 ± .023
GEPA
0.695 ± .010
OpenEvolve
0.738 ± .010
POLCA (Ours)
0.952 ± .005
POLCA reaches 95.2% (133/140), vs. the sequential baseline 0.593 (67/113).
Where the gains come from
Stochasticity (Ch. 1): updated mean scores average out variance, while baselines fix a score from one stochastic evaluation.
Memory (Thm. 2): the priority queue revisits unlucky candidates and keeps a non-decreasing best-so-far baseline.
De-duplication (Ch. 2): the ε-Net bounds the program count \(N_\varepsilon\), so parallel threads explore new regions, not near-duplicates.
Global context: the Summarizer aggregates feedback across many paths; DSPy/GEPA/OpenEvolve use only local context.
Generality: gains hold across Gemini, Claude, and weaker open-source backbones (gpt-oss-20b, Qwen3.5-122B).
06Ablations
ε-Net and Summarizer
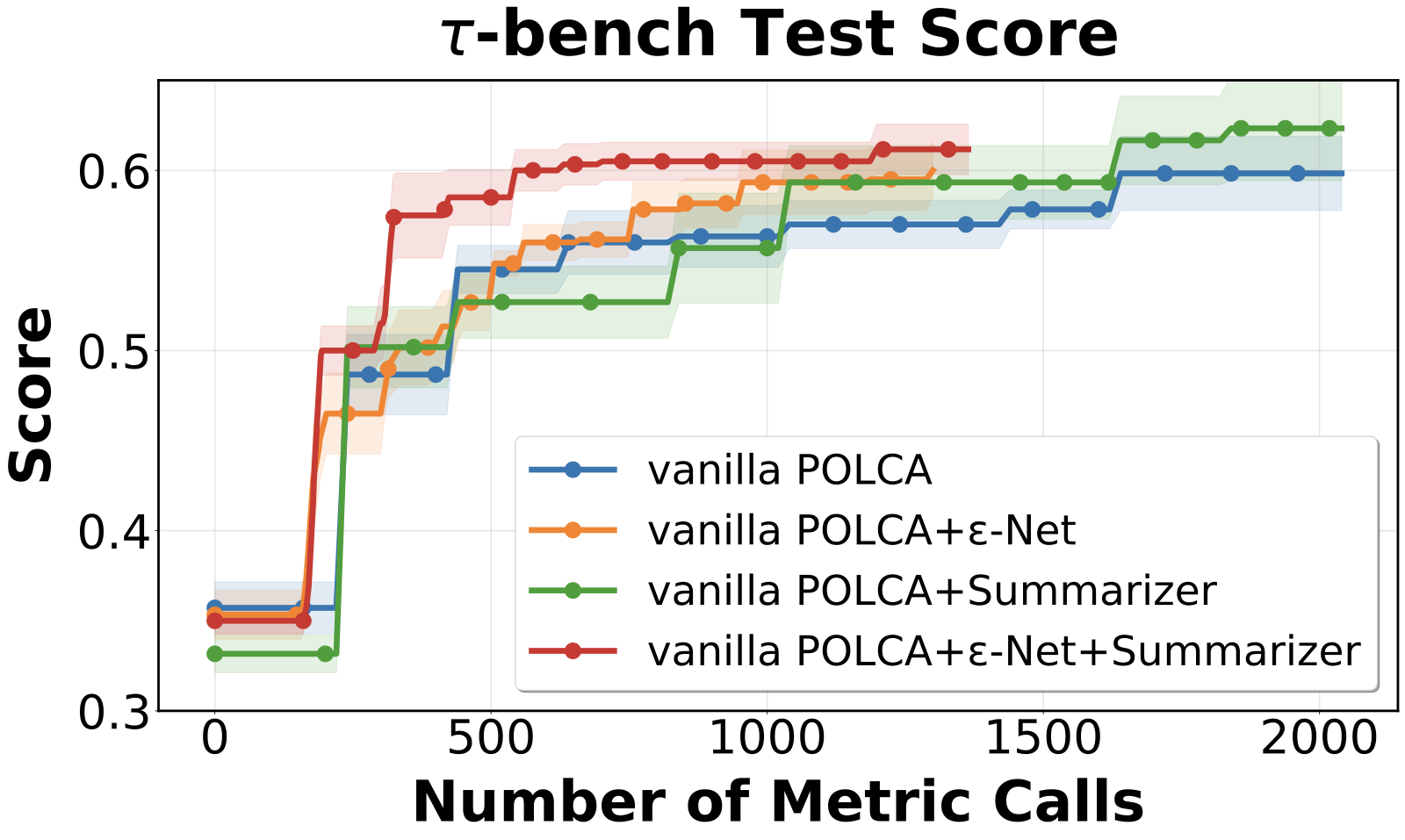
Removing either component hurts. The ε-Net conserves sampling budget by pruning semantically redundant candidates, so the same score is reached with fewer samples; the Summarizer feeds the optimizer global success/failure patterns drawn from the whole memory rather than a single program. Together they account for the gap between "vanilla" POLCA and the full method.
Figure 9. Ablation of the ε-Net and Summarizer on τ-bench (6 seeds). "Vanilla POLCA" removes both components; adding each one improves performance.
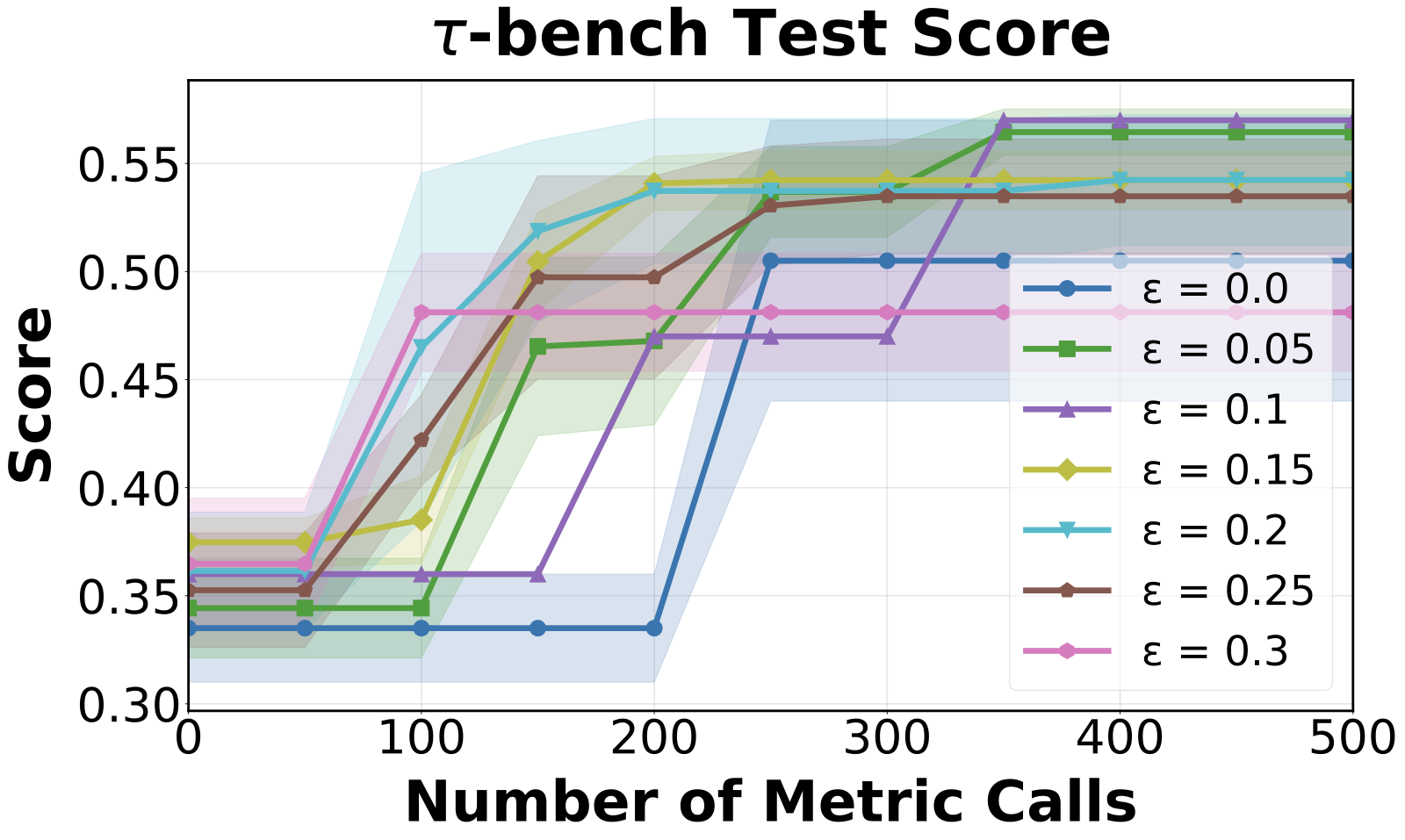
Sensitivity to the diversity threshold ε
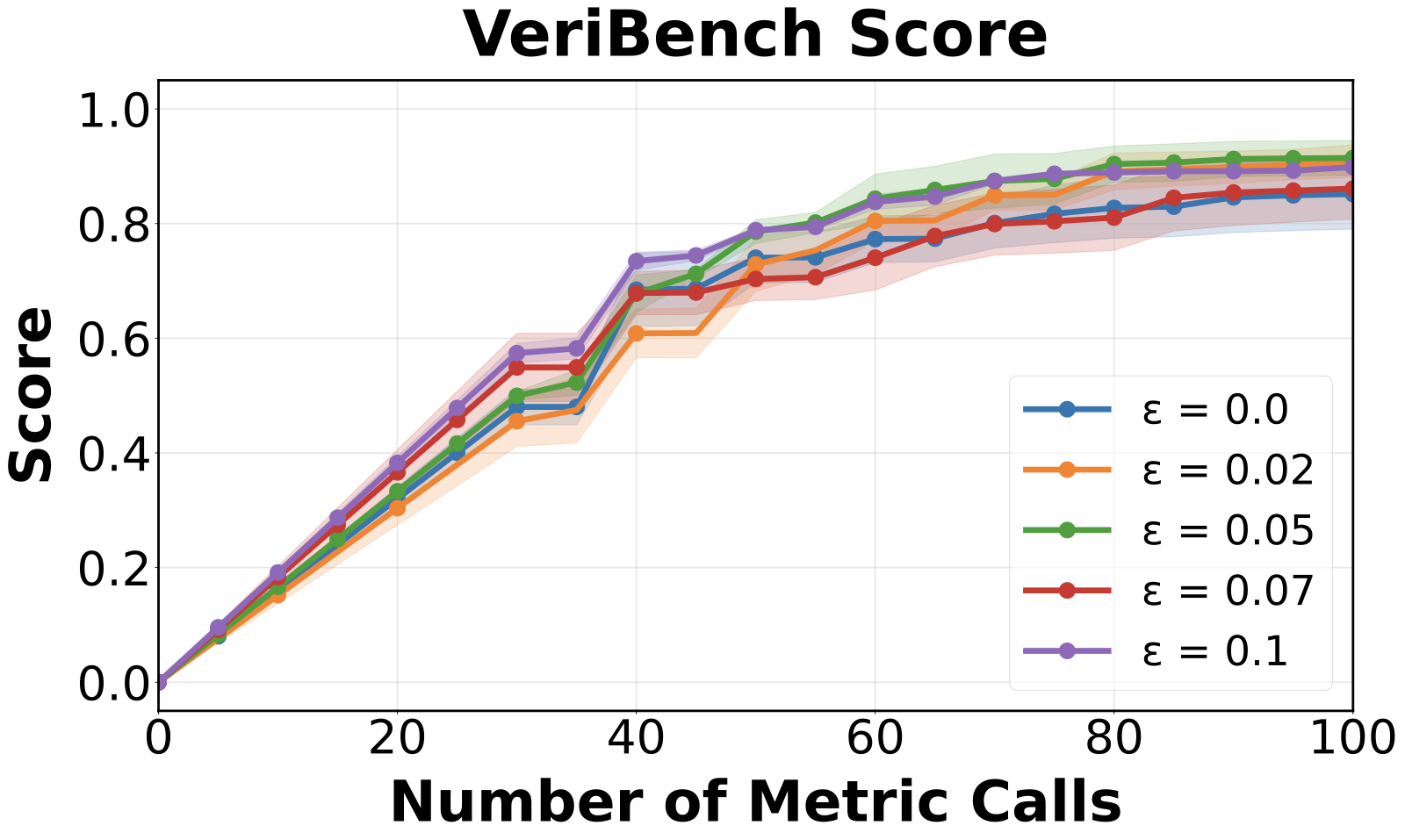
Performance is robust across a reasonable range of ε. Setting ε = 0 (no discretization, memory grows unchecked) is consistently worst; very large ε speeds up early learning but caps asymptotic performance through coarser approximation. A moderate ε buys speed at negligible cost.
Figure 10. Effect of the diversity threshold ε on τ-bench (left) and VeriBench (right).
Why not learn a reward model instead of the empirical mean?
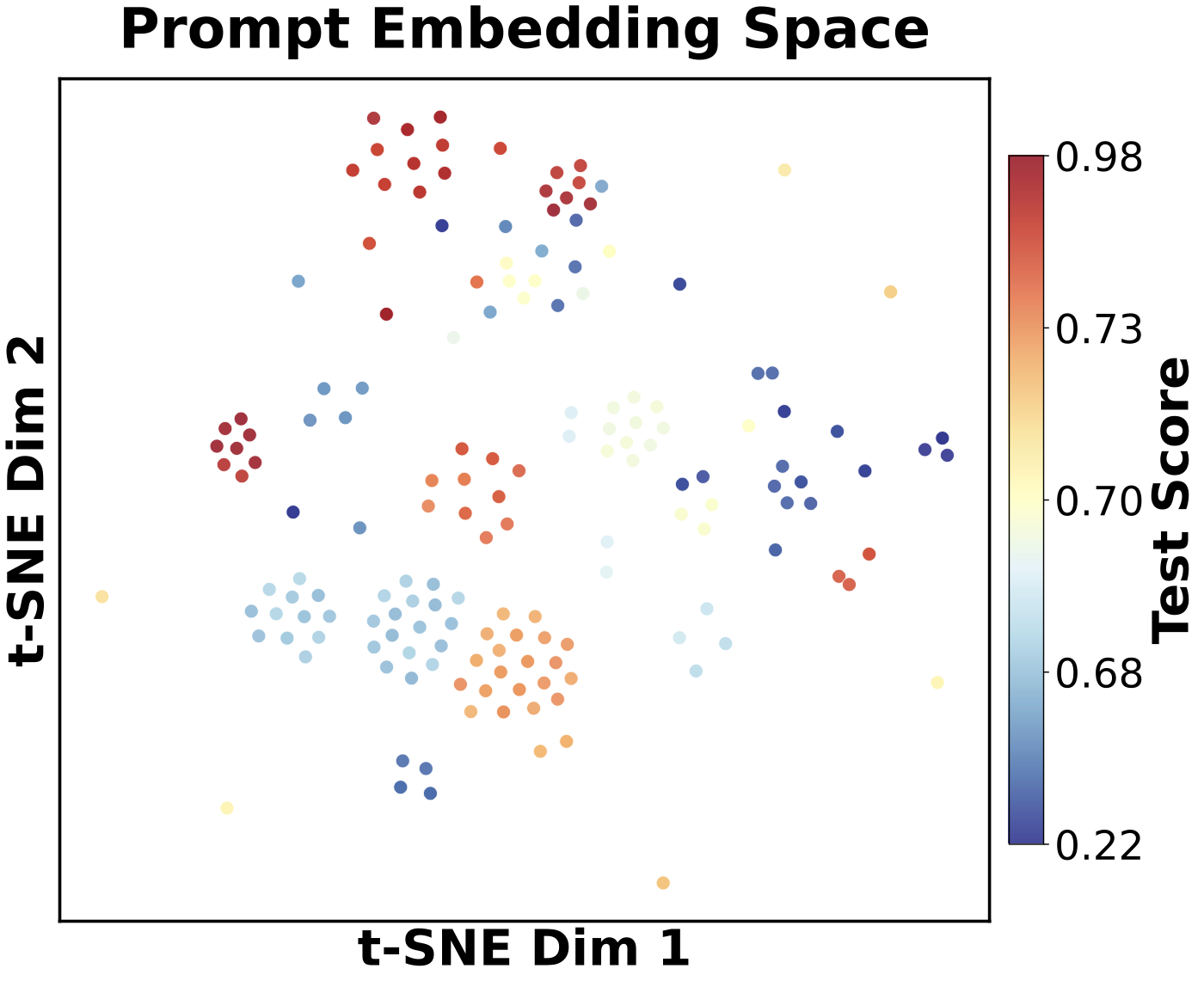
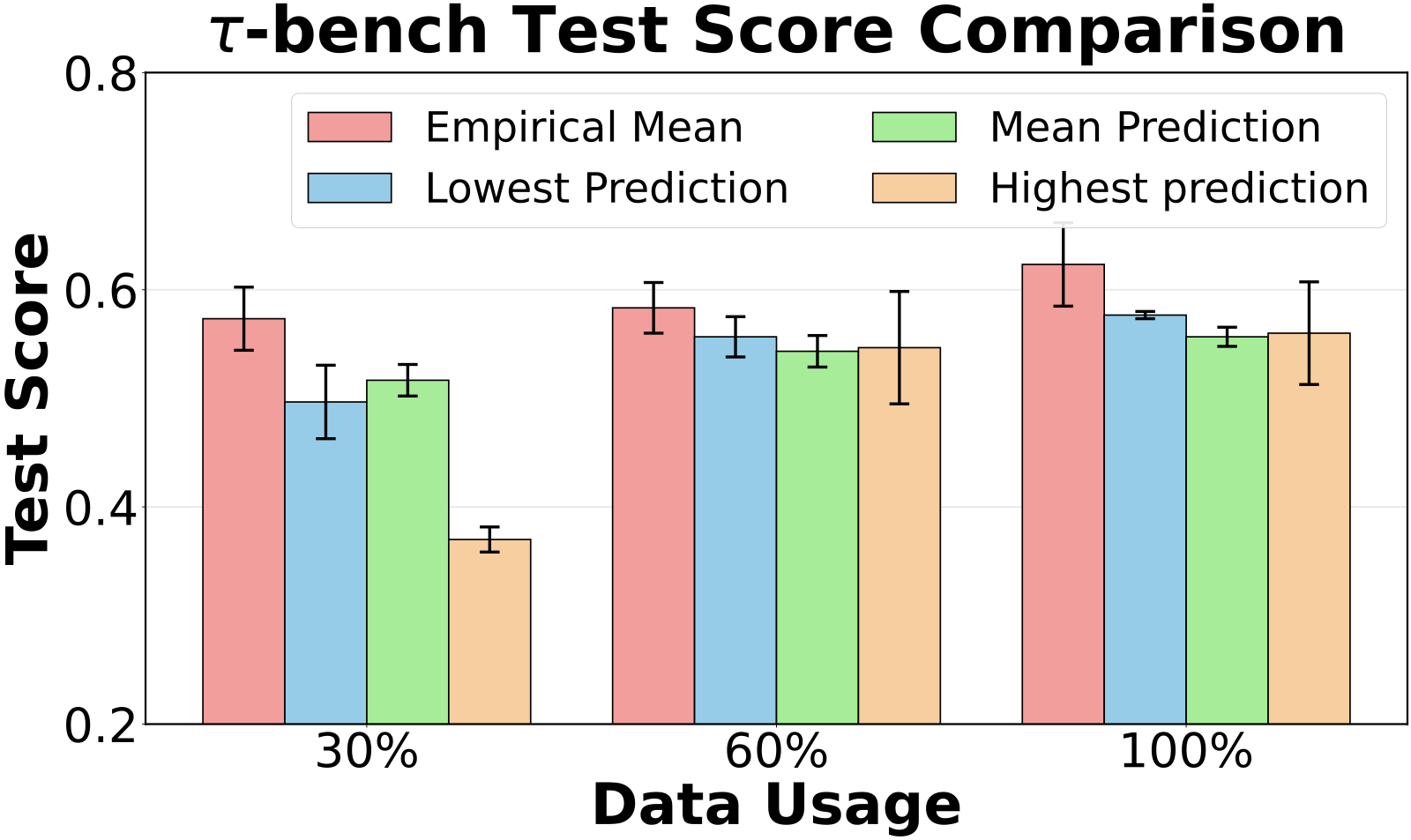
A natural alternative to re-evaluating programs is to predict their reward: train a regressor on (embedding, reward) pairs and use it to rank every candidate, exploiting the fact that similar programs have similar scores. We tested this carefully. First, the premise holds locally — a t-SNE projection of prompt embeddings collected during a HotpotQA run (Figure 11, left) shows that tightly clustered programs share similar scores, which is exactly the local smoothness the ε-Net relies on to discard near-duplicates. We then asked whether that smoothness can be pushed into a global predictor: we trained an ensemble of five \(\ell_2\)-regularized logistic regressors mapping a program's embedding to its expected reward, each on a random subset of the collected data, and selected the best program in memory by four criteria — the empirical mean and the ensemble's max, mean, and min predictions — across a range of training-set sizes, externally re-testing the chosen program for a precise score. The result is consistent (Figure 11, right): selecting purely by the empirical mean beats every regressor-based criterion. The reason is that local embedding smoothness does not extend to globally accurate score prediction — without explicit problem-instance information, a program's embedding simply does not determine its reward across the whole space, so the learned surrogate overfits the stochastic training scores. This is precisely why POLCA uses the embedding only as a reward-free similarity signal inside the ε-Net (where local smoothness is enough) and keeps a non-parametric empirical mean as the priority (where global accuracy would be needed) — rather than collapsing both jobs into one fragile regression model.
Figure 11.Left: t-SNE of prompt embeddings from a HotpotQA run, each point colored by its test score; nearby programs share similar scores, justifying the embedding-based ε-Net. Right: test score of the program selected by each criterion across training-data fractions (3 runs, ± standard error) — the empirical mean dominates every learned-regressor variant.
07Citation
@inproceedings{ren2026polca,
title = {POLCA: Stochastic Generative Optimization with LLM},
author = {Ren, Xuanfei and Nie, Allen and Xie, Tengyang and Cheng, Ching-An},
booktitle = {International Conference on Machine Learning (ICML)},
year = {2026},
eprint = {2603.14769},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}